DiTVC: One-Shot Voice Conversion via Diffusion Transformer with Environment and Speaking Rate Cloning
WASPAA 2025: IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, October 2025
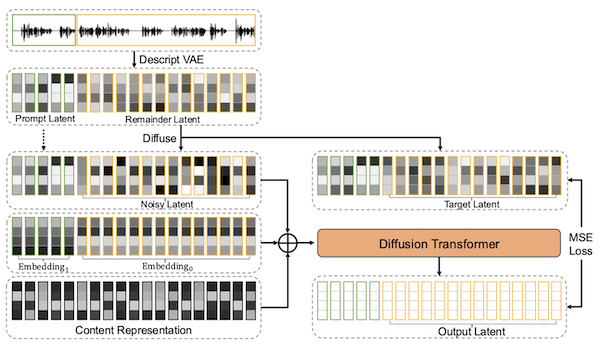
Framework of DiTVC: the input utterance is divided into a prompt and a prediction segment. The diffusion transformer takes in a noisy latent, a mask embedding, a content representation from the prediction part, and generates an output latent using the speaker and acoustic information from the prompt. An MSE loss between the output latent and the target latent of the reparameterized velocity is used for optimization. Lastly, we simulate the diffusion process and use the DAC-VAE model to reconstruct the audio waveform from the latent.
Abstract
Traditional zero-shot voice conversion methods typically extract a speaker embedding from a reference recording first and then generate the source speech content in the target speaker’s voice by conditioning on that embedding. However, this process often overlooks time-dependent speaker characteristics, such as voice dynamics and speaking rates, as well as environmental acoustic properties of the reference recording. To address these limitations, we propose a one-shot voice conversion framework capable of replicating not only voice timbre but also acoustic properties. Our model is built upon Diffusion Transformers (DiT) and conditioned on a designed content representation for acoustic cloning. Besides, we introduce specific augmentations during training to enable accurate speaking rate cloning. Both objective and subjective evaluations demonstrate that our method outperforms existing approaches in terms of audio quality, speaker similarity, and environmental acoustic similarity, while effectively capturing the speaking rate distribution of target speakers.
Links
Citation
Yunyun Wang, Jiaqi Su, Adam Finkelstein, Rithesh Kumar, Ke Chen, and Zeyu Jin.
"DiTVC: One-Shot Voice Conversion via Diffusion Transformer with Environment and Speaking Rate Cloning."
WASPAA 2025: IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, October 2025.
BibTeX
@inproceedings{Wang:2025:OVC,
author = "Yunyun Wang and Jiaqi Su and Adam Finkelstein and Rithesh Kumar and Ke
Chen and Zeyu Jin",
title = "{DiTVC}: One-Shot Voice Conversion via Diffusion Transformer with
Environment and Speaking Rate Cloning",
booktitle = "WASPAA 2025: IEEE Workshop on Applications of Signal Processing to
Audio and Acoustics",
year = "2025",
month = oct
}